ML/AI needs training data; training data comes from operations; operations need ML/AI

Imagine this: You are a businessperson living in the age of AI; you see the information revolution in full swing and you know it’ll change society as we know it. You want to be a part of this. You decide to start a business where you train an ML/AI model and charge a subscription for access.
Maybe it forecasts financial risk from a loan applicant's activity data; maybe it predicts crop yield using satellite imagery. Whatever domain it is, you have found and validated your product market fit. Now you need to build your model.
The ML researchers you hired are telling you that they need training data to build this thing; a lot of it. For the model to be accurate, that data needs to be sampled from the same specific domain your problem is in, preferably the same instance of the problem (loan default data from the same banks, historical crop yields from the same farms you will sell to). Otherwise they can't train a data driven model.
When you ask them how this data can be gathered, they tell you that the ideal data will be through operations themselves. When a client has been signed on, they will generate data to the prescribed quality and specifications that you require. After a while of operations, you will have gathered enough data to train a proper model.
And how will you be able to get a client signed on and start operations? Once you have a trained and tested model to sell. Which needs good training data. From your operations.
You are facing the cold start problem intrinsic to ML based AI.
What's happening here?
There are 3 components that depend on each other to work.
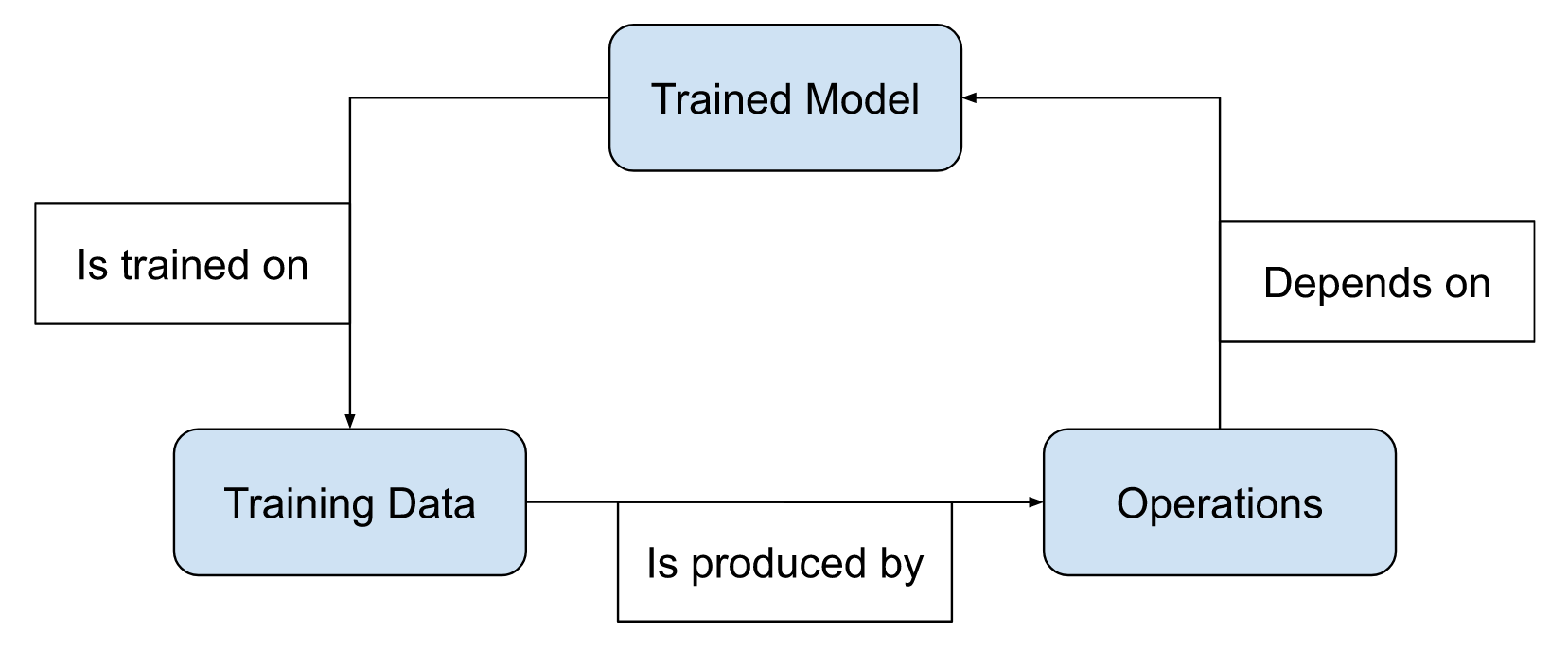
The trained model, training data, and operations all depend on each other and unless the cycle is already moving, it’s hard to get this triangle of sadness to spin and produce value. It needs to be moving for it to start moving, and so it can’t start moving. This is the cold start problem.
This is a huge problem for the information revolution as it prohibits the expansion of AI/ML enterprises. It’s hard to set up new AI businesses because you can’t get this dynamic to start spinning, and it’s hard for existing AI enterprises to laterally expand to another domain as that creates a whole new triangle of sadness that, once again, isn’t spinning.
Can investors help?
Money can’t solve this problem. Not directly.
You can’t buy information that doesn’t exist so if the training data or trained model isn’t already operational then there’s nothing for you to buy. And if the model or data are operational, then they either belong to a competitor, who will probably not sell to you, or the data could belong to a legacy operation, which may not be in the right format for you to use.
And look at the bigger picture, who will sell you the data and model that is fit for the exact problem you are trying to solve. If you are facing the cold start problem then so is everyone else in the domain.
And you can’t “buy” operations. I can’t even imagine how that would work. Pay people to use your service that doesn't actually provide them with any value yet? That won’t work. People need an immediate value add to put time and effort into using a service and logging their data. This is why no one keeps detailed track of their every minute purchase so that they can analyse and track their finances. People barely do this well enough to file their taxes. The only way to have people log data in the exact fashion you want is to provide them with a real world value add, and money doesn't cut it.
So what can an AI startup do?
The key is jumpstart the triangle of sadness at one of the 3 points.
Just like the combustion engine is a car, you can’t actually cold-start it, you have to provide some heat using something like a spark plug, until it achieves a critical heat and becomes self-sustaining.
If we can set up any one of the operations, model, or training data outside of this dynamic and then transplant it in, that will get the triangle of sadness spinning and, hopefully, go critical and become self-sustaining on nothing but AI.
So let’s look at the three points we can attack.
Operations
This is the most promising point to attack.
Most of the time, the problem being solved by AI is simply automating a manual task that is not feasible to do at a large scale or in a short timeframe. This means that a facsimile of operations can be set up where the work is done manually at first. Scaling will be bad but if you can get your AI dynamic jumpstarted soon enough then manual operations can cease before they become a problem.
Another aspect is that sometimes the data generated itself can be a non-AI value add. An example of this would be in cases of compliance or liability. In this case we don’t even need to set up any utility operations that produce data as an artefact, we can just directly set up operations to collect data. Having the data itself will be the utility and value add that will sustain the operations for long enough to jumpstart the AI.
Here’s an example to illustrate what I’m talking about: you want to set up a business where you use AI/ML to analyse in-store customer behaviour, and then produce insights and actionable advice to increase sales completions (maybe even by the in-store salespeople in real time). Well you don’t have the operations since you just started out, you don’t have the trained model, and you don’t have any data to get insights from.
What you can do here is set up the data gathering operation for a non-AI value add. To analyse shopper behaviour, you need video footage of them as they are shopping, and to get data on successful and unsuccessful sales closures, you need data about when they actually bought something. The video footage is going to be useful in detecting and proving shoplifting, and gathering the sales data is important for financial operations anyway. These two data streams are, obviously, already gathered by stores, which is why they are such an easy example. But even in more novel situations, it might be possible to detect some cases.
Once you have the operations set up for the tangential purposes, you may still need to do more to make sure the data is fit for AI operations. You see, perhaps the data artifacted from the pseudo operations is pretty close to what you need, but it doesn't have all the crucial dimensions or fields or structuring. And the operations that would produce data with those things is not justifiable to the client without an additional value-add to the client.
This is where temporary manual operations come in. The turnaround time between initial investment on the new data pipelines and the production of actionable insights will be much quicker with a manual pseudo consulting operation that fills in for the AI model. This will obviously scale very badly, and cost a lot of money, but will also produce the perfect training data as it operates. Then it’s only a matter of time before an AI can be set up to begin operations in earnest.
This way, a spark in the operations element can start pushing our triangle of sadness, and each subsequent element that gets pushed (receives value) exerts more force in the same directions, and pretty soon it starts spinning on its own.
Training Data
This would not be as feasible.
The idea here would be to somehow find someone already performing the exact operations needed to produce the training data your AI needs. This will be hard to find because that person would face the same AI cold start problem as you, and it might be infeasible to do the task manually.
But even if you do find a traditional operator in the relevant domain who is solving the relevant problem with manual operations and producing the relevant data, gaining access to it might be difficult. That business would already know the value of the problem being solved (they are already solving it or at least something adjacent to it) and would see that their data is a critical ingredient in your enterprise, and they might want a stake in it.
This might be ok for you, but I don't know how feasible it would be to give up equity for training data. Given that the largest and most successful data operations in the world (content recommendation, language modelling, image modelling) are done on a companies own data, or data that is freely available online, it seems the market simply does not support these types of partnerships. There’s probably a good reason for that, it does not seem like a good deal.
AI model
A few years ago I would have said that this is ridiculous, but with the rise of large transformers (LLMs and diffusion models) and their emergent capabilities, I can’t be as sure anymore.
Are there tasks out there that a multi-modal LLM can start to solve and label? As of writing this , I would say not yet. But there’s a possibility that that might not even be the case by the time you read this. That's how crazy the industry is these days.
But if I had to guess, I’d stick to my point in the linked post above that these LLMs are trained on word associations and, while that does allow them to learn quite a bit about the real world, it simply isn’t enough to learn how to tackle more complex tasks at a human level. We would need some sort of AGI for that and these large transformers aren’t it.
TL;DR
- AI based businesses face a cold start problem when they try to offer value to users through AI models
- The AI needs to be trained on data from the problem it's meant to solve. Collecting that data requires operationally solving that problem. The problem can't be solved at scale without AI.
- This prohibits lateral expansion of ML/AI
- No, you can't throw money at the problem
- This stationary triangle of sadness needs to be hacked at one of the nodes to get it spinning
- Jumpstarting the operations is most feasible, where some value should be offered through more data economical tools (even non-ML if possible) to start collecting training data.
- Jumpstarting training data might be possible, but is heavily dependent on client cooperation.
- Jumpstarting the AI might be possible with large unsupervised transformers but that isn’t a certainty