Machine learning isn't always the right solution to a problem

Machine learning is an attractive proposition because it reduces the risk of solution model engineering. An analytical and hand-crafted solution model depends very heavily on a “eureka” moment which may or may not come. But a machine learning algorithm (especially deep learning) can depend very little on the insights, assumptions, and heuristics that a solution architect would need to come up with.
The pursuit of this risk mitigation can in fact lead managers, owners, and investors to see every problem as a nail that can be handled by the machine learning hammer. A professional, or research bias can lead engineers to do the same. But some problems might not be model-able by the current arsenal of established machine learning algorithms. and the decision to attempt a more analytical approach for these requires a more judicious consideration than normal.
A very good example of these sorts of problems is dynamically determining prices for services in a market where the price is very dynamic. Rideshare pricing is such a situation and there have been multiple approaches to this. Uber, Lyft, and Careem have applied an ML based algorithm, which is a bad way to model this problem. InDrive has instead utilized a bidding based solution, which is a model that has a very high fidelity to the natural process by which prices are determined. The latter is the right solution to the problem
Having the right solution to the problem will minimize the situation where your model of the situation and the actual situation do not line up. These situations leave your users disillusioned, and decrease their trust in your ability to give them a reliable answer to the problem.
Why even use machine learning?
I don’t want to give the impression that I think machine learning is not useful. Given the amazing things being achieved by ML, that would only make people think I'm a fool. And that’s a secret I intend to take to the grave. The reason we use machine learning is that it offloads some of the work needed to model a problem. This is because ML researchers develop algorithms that learn a solution to a problem, instead of being the solution itself.
Take the example of linear regression, that is to say, the problem of predicting Y from X when you know (or can assume) that Y will be directly proportional to X (doubling X doubles Y). Now that you did all the work to confirm that that relationship is true, it just seems tedious to have to actually figure out exactly how much Y increases by if X increases by one, and what the value of Y is when X is zero. You could guess these values and adjust them according to how well they perform in production. You could use historical data to make the initial guess even better, but wouldn’t it be nice if someone smart just figured out a way to automate that guesswork?
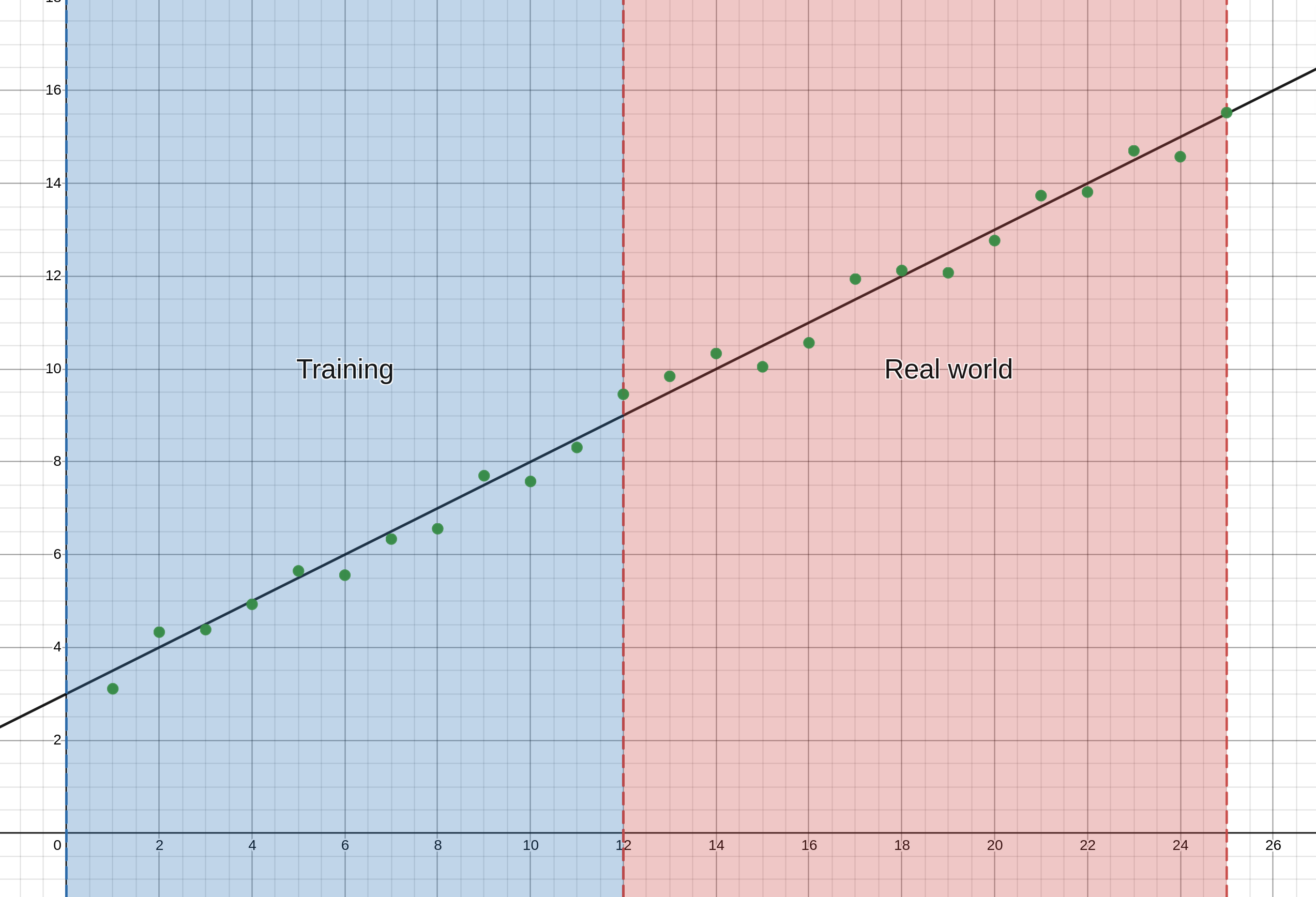
Well, someone smart did, in fact, do this. Someone very smart actually. And this means that now you and I can just confirm that a problem does, in fact, fall within the umbrella of linear regression, and then just let this ML algo figure out the rest using historical data. No risk of my lack of experience with the specific domain meaning I get these parameters horribly wrong. And no more tedious calculations.
This is exactly how deep learning models like LLMs work. We have a very good guess as to how language is modeled, and a great idea as to how to implement that model, but it’s just not feasible for us to sit there and calculate the necessary values, or guess them from historical data. So it’s very lucky that some very smart people discovered a way to learn a good guess for these values automatically. Think about how amazing chatGPT is to see how well this has worked out.
Then why even use anything other than machine learning?
You’d think so, wouldn’t you?
It’s tempting to think that. When we try to model a problem by hand, we have a limited amount of time and effort to put into testing out each and every hypothesis we might have. So we have to be very clever in coming up with these hypotheses. There is a right answer, and we need our guess to be as close to it as possible. And the person modeling the problem needs to be smart to do this effectively and reliably.
This can create a huge risk for the people who pay the salaries for these modelers. Imagine you paid top dollar to secure a highly sought after researcher to model a problem for you and then they just don’t have the eureka moment needed to solve it. Not even because the person wasn’t smart enough, but because a eureka moment like that can be a coinflip that researchers spend entire careers chasing and the coin did not flip your way. Imagine if you had to model exactly each and every way one word could relate to another word. Now imagine if you didn't come up with all the possibilities. Your LLM would be incomplete and would just not be able to perform to the level we know it can.
If you, as an employer and businessperson, could mitigate this risk then that would be godsent. ML allows you to do just that. ML takes care of a lot of the riskier, lower level aspect of the model. A neural network with billions of parameters can just try a lot of random hypotheses and backpropagation can make sure that each successive hypothesis is better at solving the problem. This leads to the model being probably correct. I don’t. This means that it eventually comes to something pretty close just by brute force. Brute force is expensive but it’s not risky.
But there is no such thing as a free lunch. If something seems too good to be true, then you should be a bit suspicious of it.
Then how can ML ever fail?
Through the risk that the ML algo you're using was never meant to work on the problem you're trying to solve.
These ML algos still have limitations, these limitations are in the form of assumptions made about the process the algo is modeling. In the previous example with a linear regression, a huge assumption was that Y is directly proportional to X, meaning they have a straight line relationship. What if that just wasn't true? Well then your model would fail catastrophically.
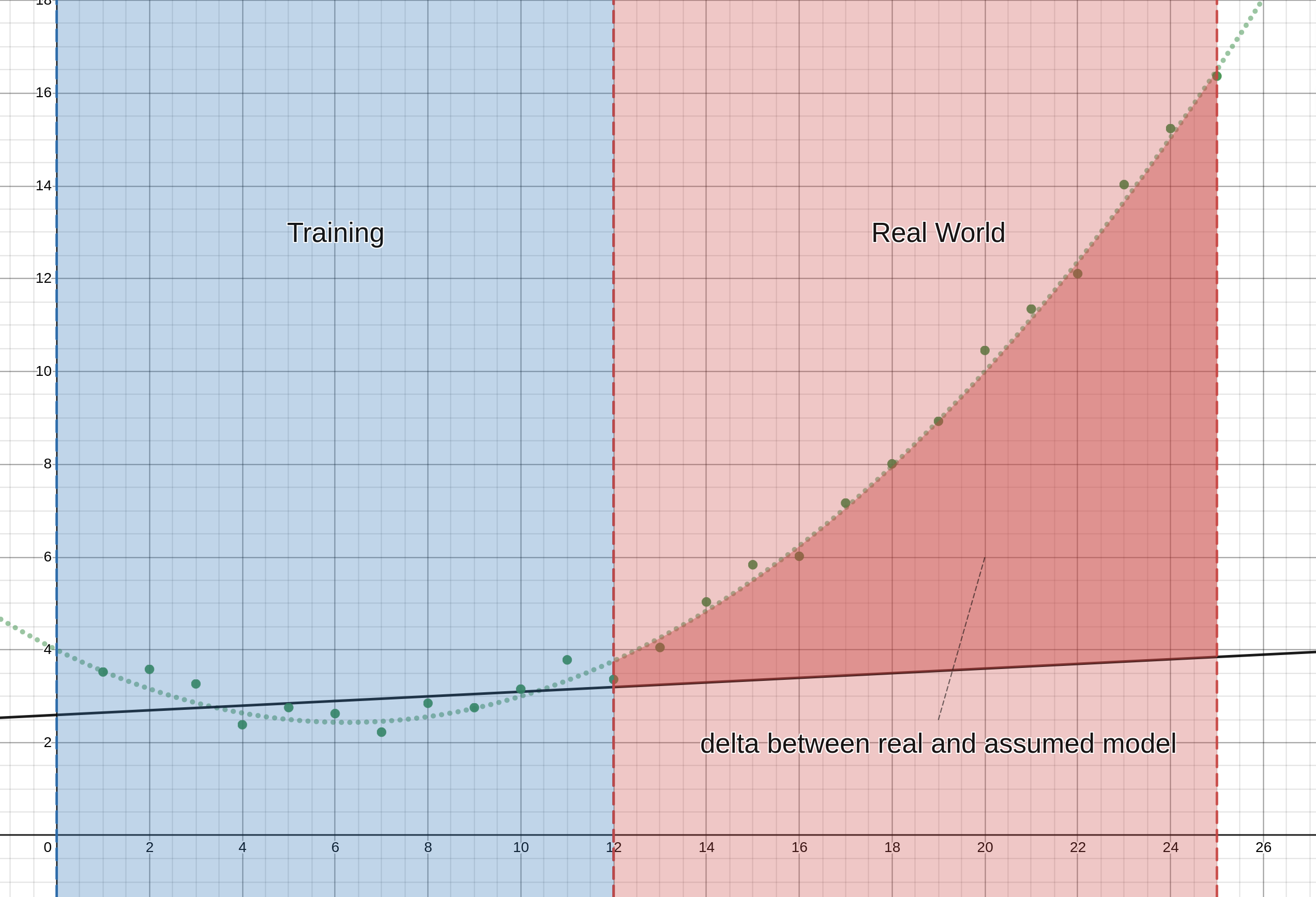
Mark Twain once said "it ain't what you don't know that gets you in trouble, it's what you know for sure that just ain't so". That's exactly what's at play here. Software, including machine learning algorithms, is made under certain strong assumptions. Violating these assumptions will result in the whole system giving results that don't make any sense.
Sounds obvious. How could anyone mess that up?
It's not obvious and people mess it up all the time.
The example above is very simple. It's easy to detect too, if you already know what you're looking for. But your idea of the problem is a model as well. And once again, it's what you don't know that'll get you in trouble.
Consider the more complex case of static data generating functions and dynamic data generating functions. In short, a static process does not depend on your algorithm's previous prediction or action regarding the process. Like how if you read a book, the text on the next page doesn't change depending on how you chose to interpret the previous page. A dynamic process on the other hand can change depending on your algo's previous predictions/actions. Like how if you think a stock is going to fall soon, and you decide to sell a lot of it, the price of the stock will fall simply because you sold a very large amount and that significantly increased supply. If you think that's trivial, I invite you to wrap your head around the mathematics involved in GameStop and the legend of u/DeepFuckingValue.
Dynamic systems like this are currently the prime example of systems that are absolutely not modeled by tried and tested ML. (Reinforcement learning does model this but it's not mature enough and its training is not scalable for most domains that need it). And economic systems are even more exemplary because they are all purely made of dynamic systems. So much so that economists often try to simplify them to static systems by assuming infinite liquidity, which can sometimes be like assuming spherical cows.
One such case is pricing for rideshare services. This is a very dynamic system that is affected by environmental factors as well as the state of multiple economic agents (the driver and the rider). These mean that prices need to be decided at a very high resolution in multiple dimensions. You need different prices for every source and destination location, for every hour of the day, for every vehicle type, and so much more. This can not be done manually, it has to be automated
The dynamic nature of the system means that any algo would need to model the conditions of the environment, the states of both agents involved, as well as how the agents themselves model what their actions should be.
Again, the modern arsenal of feasible ML algos don't model these things. They were never made to do so. But that didn't stop Uber and Lyft from doing just that. These companies probably decide prices based on a mixture of manually crafted heuristics that fail to generalize, and ML algos that are designed for static systems.
This is the wrong way to solve this problem. That's not to say that it'll be particularly harmful. All models are wrong, some are useful, and this model may be useful enough that no one cares if the price is a bit off. But that doesn't change that there is a more right way to model the problem. A way that has a higher fidelity to how the market naturally decides prices
What is the right model then?
The way the market naturally does it: let two diametrically opposed agents negotiate a price.
These two agents are the buyer and the seller. If you want to buy something, you will find a seller. Then you, or the seller, will propose a price for the product. The other party will counteroffer another price (either explicitly by bartering, or implicitly by not buying the product). And both parties will decide whether the price is acceptable to them by considering two things: whether the price has a positive delta with the value of what is being exchanged, and whether other buyers/sellers will offer them a better price. These symmetrical and opposite incentives create a stable equilibrium for the price that is acceptable to both parties (assuming the sale has a positive value proposition for both, which is a different story altogether).
That's how InDrive models their ride price. There is a bidding system where the driver and the rider (the seller and buyer) both propose prices to each other. And the rider gets bids from multiple drivers to compare prices and the driver gets bids from multiple riders to compare prices.
The clever thing about this model is that it correctly accepts that there is no way to model the incentives and policies of the two agents, and does not even try. It then very cleverly uses the actual real agents themselves and allows them to enact their own policy decisions in the negotiation.
One criticism might be that the system doesn't facilitate riders who don’t care enough to negotiate. But, in principle, that is not true: the model generalizes to this case by not making the rider negotiate but giving them the option to. The rider can still not negotiate and just accept the first bid a driver makes. I will, however, admit that, practically speaking, this does make the user click more buttons than if a price was decided for them, which is sacrilege in UI/UX design. Good thing I don’t care about the theory behind UI/UX design.
What this system does offer, however, is an organic balance that not only solves a lot of the bugs that a normal ML algo would have, but also inspires trust by virtue of very transparently being the right model.
The model solves a huge problem that rideshare companies have when deciding price: whether to favor the rider or the driver, and taking the blame for doing so. Uber and Lyft have to play the same delicate balancing act that any platform that facilitates a service market, like doordash. That game is to keep prices low enough to keep buyers happy, but high enough to keep sellers happy. And dealing with the fact that if either party isn’t happy, they will blame the platform. InDrive does not have to deal with this problem as the buyers and sellers have the agency to decide the price and so take the blame on themselves. They are also willing to be more forgiving to each other as they understand that the other party is trying to get a positive value proposition in the sale just like they are.
The system inspires trust from the two parties as they can see that it is simply the same process that humans have used to decide prices since time immemorial. People trust it because while all models are wrong, and some are useful, the original process itself is tautologically perfect. It is trivial to show that the original process models itself perfectly, as the metric for a model’s “goodness” is how well it aligns with the original process.
This offers a very good example of using the right model for the job, not simply because it uses the original process itself (the absolute best model), but because it avoids the pitfall of using an a model outside its scope of design, just because it's the right model for a lot of other common problems.
TL;DR
- Machine learning is a very versatile tool, but people forget its limitations
- Certain problems are well modeled by ML, others aren’t
- people must let go of their biases and use the right approach, even if it isn’t ML
- A great example is prices for rideshare, which ML is the wrong solution for
- Uber and Lyft use ML algos to decide ride price
- InDrive uses a bidding system, which is the exact right way to model prices in a market
- The right model for the problem avoids unnecessary modeling errors and builds trust
- You need to use the right model, not your favorite model