Deep Learning is not magic, you still need to model the problem
Artificial Neural Networks with a large number of parameters (known as Deep Neural Networks) are obviously very powerful supervised machine learning models. The idea behind them is that they can learn not only the relationship between input features and the prescriptive labels, but also learn how to create input features from raw data in the first place.
Theoretically, such an architecture is general enough to model almost any problem (that can be expressed as a deeply nested series of linear combinations). The data scientist would only have to feed in a sufficiently large amount of training data; there would be no need to actually hypothesize about the problem. This is not the case in practice: slapping a huge (deep) feed forward NN on a problem will generally not be enough. A person will have to reason about the problem, formalize some intuitions and then encode them into the model.
These intuitions are encoded into the model by constraining them in order to create variants such as Convolutional Neural Networks, Recurrent Neural Networks, and Transformers (attention based NNs). The fact that these variants exist shows that we can not take our hands off the wheel yet. To some degree, we still have to model the problems intuitively.
But deep learning is amazing
It absolutely is.
A feedforward NN is the most general form of Artificial Neural Network and, if sufficiently large enough, can theoretically model anything that can be expressed as a nested series of linear combinations.
So if you can’t express it as “Y = aX + b”, then you can add another layer and input feature and try to model it with “Y= a(cX + cZ + e) + b” and so on until you have enough dimensionality that your problem’s underlying data generating function is a specific form of your model’s general equation.
You can go for complete overkill and have your model be way more complex than the problem, and just let it figure out which parameters it should keep at zero to constrain itself to your problem. A trivial example would be to train a large neural net to add two numbers together. This isn’t advisable, but the fact that it works is anecdotal evidence that simple NNs can model a lot of complex problems.
Simple feedforward NNs are also great because they require basically no human intuition coded into them. For context, data models get all their information from a combination of two sources: their training data, and the intuitions/assumptions encoded in their design.
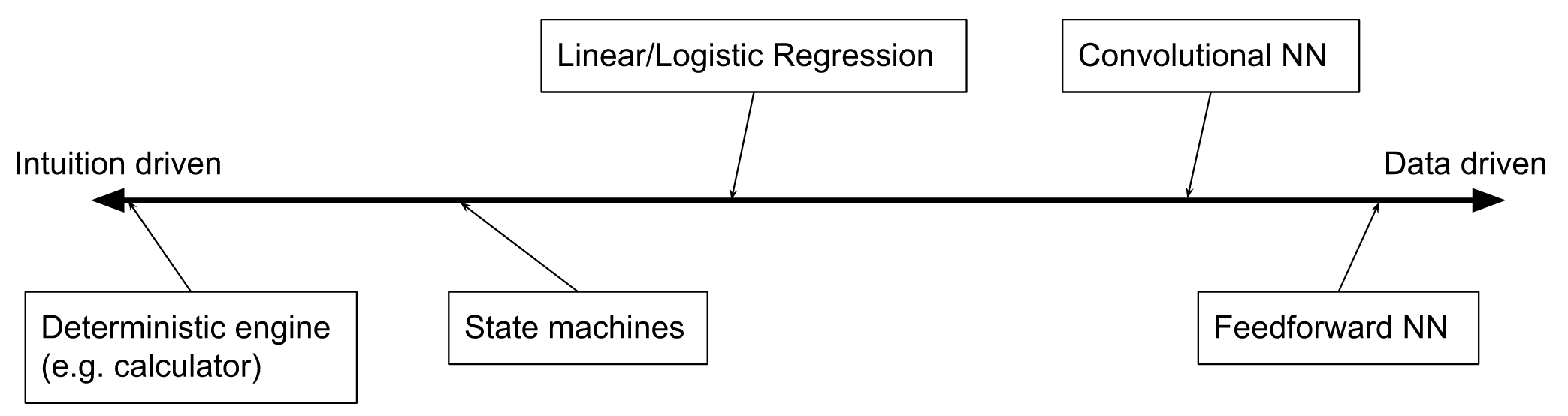
So a model for a problem that is completely deterministic and can be explicitly expressed will be something like a calculator to add two numbers together. This “model” will get all of its information from the assumptions encoded into it, i.e. the algorithm of addition; it does not need any training data to learn more about the problem.
A Linear Regression model, on the other hand, is further in the middle of the spectrum because while it has some very strict assumptions about the problem (that the input and output have a linear correlation) it does not assume the specific parameters of that line (how steep the line is and where it is on the graph): it instead learns the most effective gradient and intercept by fitting that assumed relationship on to some training data.
And then something like a feed forward NN gets very little information from the assumptions in its encoding. I guess it knows that the problem is in fact a function, and that function will be a large and complex linear combination of the inputs. But the linear combination it is encoded with is generally so large and high dimensional that it has to learn everything from the training data. And the complexity of the linear combination can be used to model things that are not linear combinations (square roots, or step functions) by learning just the right set of parameters.
A purely data-driven model like deep feedforward NN can even emulate simpler models like linear regressions by just learning to selectively set most of its weights to zero, thereby creating a layer that encodes the simple “Y = mX + c” equation. We would not have to encode that manually, it would just learn it. That is the ultimate promise of deep learning
So deep learning can do anything, right?
Should? Yes. Can? No.
In theory, a deep enough simple feedforward NN should be able to process images and do things like read handwriting and detect and classify objects. But, in practice, they aren’t able to. In order to solve those problems, we needed to invent Convolutional Neural Networks, which are a variant of deep feedforward NNs that incorporate Kernel Convolutions so as to process the image better.
It is important to note what happened there: a pure deep learning approach was not practically effective. The most effective way was for ML researchers to look at traditional image processing models and combine them with deep learning.
To be clear though, the purely intuition based explicit modeling in traditional image kernels would have been even worse, because a human simply couldn’t hard code a set of weights for it that would recognize a photo of a dog from any angle a person can. The researchers had to learn those convolutional matrix weights through deep learning. And my point is not that deep learning is useless, it’s that pure data-driven deep learning is not enough.
In order to encode the more effective convolutional layer into the NN, the researchers had to constrain the incredibly flexible equation governing the feedforward layer. In order to model a kernel convolution “scanning” across the input image left-to-right and top-to-bottom, they essentially had to set all the weights not involved in the convolution to zero (that exact method would be very inefficient, they would have implemented it in a way that was mathematically equivalent).
By manually assigning values to weights according to the hypothesis that kernel convolutions would process the image better, the researchers violated the core promise of pure deep learning. They added information to the model based on intuition rather than data.
Consider the intuition-driver vs. data-driven model spectrum mentioned above. By putting constraints on the model, they slid it closer towards being intuition-driven and further away from being data-driven. And the fact that it worked very well argues against the idea that “more data-driven = better”.
The same thing applies to Recurrent Neural Networks and Transformers. Theoretically speaking, a large enough feedforward NN should be able to learn that it should emulate the sequential and attention mechanisms when the problem demands it. But just like how they couldn’t emulate kernel convolutions, they could not constrain themselves to those mechanisms. And when that intuition was hard coded in, the model performed way better on those respective tasks.
So deep learning is useless?
Absolutely not.
My argument was never that deep learning is not a good technique to use. I think deep learning is the single most impactful technique used in the above mentioned models, and by a lot.
My argument was that it is not magic. It is not a silver bullet that will solve any problem on its own with enough resources because we can’t give it enough resources in practice.
The promise of a purely data-driven model is alluring, and would be great if it was practical right now, but it isn’t. This is something that is easy to forget when confronted with complex and hard to model problems. But as the immediate and discrete advancements in AI fueled by CNNs and Transformers have shown, some modeling is necessary to help the NN architecture learn in practical settings
Why don’t large feedforward NNs learn this themselves?
This is a very interesting question. Theoretically speaking, it should have been possible for a large enough NN to learn to constrain itself to these specific architectures (or something even better), essentially performing this modeling task automatically. That’s the point of feedforward NNs, they fit a huge linear combination onto the training data.
The fact that they didn’t is something that would need investigation from a more academic perspective, because this is something that industrial research just doesn’t concern itself with. The question asked in most of industry is “does this paper’s model learn to solve our problem”. We need academics (sometimes sponsored by industry) to ask “how does something learn to solve these problems”
I work in industry so do not really have an answer for that. I hope to learn more about that in the future, but right now, I don’t know why feedforward NNs don’t model all the problems they could have.
TL;DR
- Deep NNs are a great model with many degrees of freedom
- This should theoretically model any problem that is a large linear combination of latent parameters
- In practice, they are not able to learn efficiently enough
- Constraints have to be put on them
- CNNs, RNNs, and transformers all put constraints on deep NNs to great effect
- These constraints are eureka moments from observing natural analytical processes (i.e. human thinking)
- These modeling efforts are still needed, deep NN’s theoretical capabilities aren’t practically reliable
- It is interesting to consider why it can’t practically learn everything we thought it could